

We're Sequin, a Postgres CDC tool to streams and queues like Kafka, SQS, HTTP endpoints, and more. A lot of our users use Supabase, so we've explored all the ways they've done event-driven workflows before Sequin.
Supabase makes it easy for your frontend to react to changes in your database via its Realtime feature. But outside the frontend, there's lots of reasons your application might want to react to changes in your database. You might need to trigger side effects, like sending users an email, alerting admins about a change, or invalidating a cache. Or you might need to capture a log of changes for compliance or debugging purposes.
Realtime is just one way to respond to changes in your Supabase project. In this post, we'll explore the options available. Hopefully I can help you choose the right solution for your needs.
Database triggers
Postgres triggers execute a specified function in response to certain database events.
Postgres triggers are a part of the lifecycle of rows. You can write functions in PL/pgSQL and have Postgres invoke them whenever a row is inserted, updated, or deleted. They're a powerful way to chain database changes together.
For example, here's a trigger that maintains a search index (search_index) whenever an article is changed:
CREATE OR REPLACE FUNCTION update_search_index() RETURNS TRIGGER AS $$
BEGIN
IF TG_OP = 'INSERT' OR TG_OP = 'UPDATE' THEN
INSERT INTO search_index (record_id, content)
VALUES (NEW.id, to_tsvector('english', NEW.title || ' ' || NEW.body))
ON CONFLICT (record_id) DO UPDATE
SET content = to_tsvector('english', NEW.title || ' ' || NEW.body);
ELSIF TG_OP = 'DELETE' THEN
DELETE FROM search_index WHERE record_id = OLD.id;
END IF;
RETURN NULL;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER maintain_search_index
AFTER INSERT OR UPDATE OR DELETE ON articles
FOR EACH ROW EXECUTE FUNCTION update_search_index();
What's really neat about triggers is that they run in the same transaction as the change they're triggering off of. So, if a trigger fails to execute, the whole transaction is rolled back. That can give your system some great guarantees. (Said another way, triggers give you "exactly-once processing".)
This means triggers are great for:
- Maintaining derived tables (like search indexes)
- Populating column defaults (where
defaultdoesn't cut it) - Creating audit logs of changes
- Enforcing business rules
When are triggers not a good fit?
What makes triggers great also makes them weak for certain use cases.
First, they can impact database performance. A great way to eke out more performance from Postgres is to batch operations. But triggers are executed one-by-one, row-by-row, sometimes blunting the benefits of batching.
If you're not careful, one insert can lead to a cascade of changes across your database. Naturally, the more tables Postgres has to visit to make your insert possible, the slower those inserts will become.
Second, Postgres triggers are relatively easy to write thanks to tools like Claude Sonnet. But they're hard to test and debug. PL/pgSQL isn't the most ergonomic language, and triggers aren't the most ergonomic runtime. With some database clients, one of the only tools for debugging is sprinkling raise exception 'here!' throughout your codebase. This can be a headache.
Third, and perhaps most obviously, Postgres triggers are limited to your database runtime. They can only interact with the tables in your database.
Unless...
Database Webhooks
Database Webhooks in Supabase allow your database to interface with the outside world. With the pg_net extension, you can trigger HTTP requests to external services when database changes occur. The pg_net extension is asynchronous, which means database changes will not be blocked during long-running requests.
Here's an example of a Database Webhook that fires whenever a row is inserted or updated into the orders table:
CREATE OR REPLACE FUNCTION post_inserted_order()
RETURNS trigger
LANGUAGE plpgsql
AS $$
BEGIN
-- Calls net.http_post function
-- Sends request to webhook.site
PERFORM net.http_post(
'https://api.example.com/my/webhook/handler'::text,
jsonb_build_object(
'id', NEW.id,
'name', NEW.name,
'user_id', NEW.user_id
),
'{"Content-Type": "application/json", "Authorization": "Bearer my_secret"}'::jsonb
) AS request_id;
RETURN NEW;
END $$;
CREATE TRIGGER inserted_order_webhook
AFTER INSERT OR UPDATE ON public.orders
FOR EACH ROW EXECUTE FUNCTION post_inserted_order();
Database Webhooks make Postgres triggers a whole lot more powerful. You can send webhooks directly to workflow tools or to non-JS services in your stack. You can use them to trigger serverless functions, like Supabase Edge Functions.
You can use Database Webhooks to move complex triggers from PL/pgSQL to your application code. For example, you could use a Database Webhook to notify your app of a recently placed order. Then your app could run the series of follow-up SQL queries to modify other tables as necessary. While you could do this with a plain database trigger, this lets you write code in your domain language – where you can easily unit test, debug, etc.
When are Database Webhooks not a good fit?
While Database Webhooks allow you to move more business logic into your application code, the setup process will still take some trial and error. I recommend getting your requests to work first by running them directly in Supabase's SQL Editor (e.g. run perform net.http_post...) Then, once you're confident that you're shaping your requests the right way, you can embed the call into your Postgres trigger.
Second, unlike Postgres triggers, pg_net calls are async. This is good, because it means there's little performance overhead. But bad because pg_net offers at-most-once delivery. That means if something goes wrong or your webhook endpoint is down, the notification might get lost for good. Supabase will store the error in a dedicated table for 6 hours, but won't automatically retry the webhook.
Third, there are some reports of pg_net failing to make requests after your database transaction volume surpasses a certain threshold.
So, while Database Webhooks expand the possibilities of triggers, they're not a replacement. You'll want to continue to use triggers for those critical in-database workflows where you 100% can't miss a change.
Realtime Subscriptions
Realtime is Supabase's flagship feature for reacting to database changes. It allows both client and server applications to subscribe to changes in your database tables and receive updates in real-time.
First, be sure to turn Realtime on for your table:
Then, you can create subscriptions. Here, we specify a subscription for INSERT operations on orders:
// Listen to inserts
supabase
.channel('default')
.on('postgres_changes', { event: 'INSERT', schema: 'public', table: 'orders' }, payload => {
console.log('Received change', payload)
})
.subscribe()
Realtime's easy to use and you can use the same client interface on both the frontend and the backend.
Unlike Database Webhooks, Realtime is a pub/sub system. You can use it to broadcast changes to many clients, which is great for building reactive interfaces. And clients can even broadcast their own messages, making Realtime a powerful tool for building collaborative features.
Compared to Database Webhooks, I find Realtime a bit easier to work with, in part because it's well supported in Supabase's console and JavaScript client.
When is Realtime not a good fit?
Like Database Webhooks, messages have at-most-once delivery guarantees. So it's not a good fit when you absolutely need to react to a change. You need to be comfortable with the fact that messages will be dropped (for example, your Node app wasn't subscribed).
While you can use Database Webhooks to trigger side effects and async workers, that may not be the best use case for Realtime. With webhooks, you know your request was routed to at most one worker, and so only one worker will field your request. But with broadcast systems like Realtime, multiple workers might pick it up. So if you wanted to use Realtime to, say, send an email, that could result in some undesirable situations: multiple workers hear about the request and send out an email. (You can try to mitigate with private channels, but how do you mutex message handlers on deploys?)
Listen/Notify
Postgres' built-in pub/sub mechanism, Listen/Notify, is a simple way to broadcast events:
-- In one session
LISTEN my_channel;
-- In another session
NOTIFY my_channel, 'Something happened!';
You can call NOTIFY within trigger functions to alert listeners of changes.
However, I don't think it's the best fit for Supabase projects. First, Listen/Notify doesn't work with the Supabase JS client and doesn't work with Supabase cloud's connection pooler. But more important, everything that Listen/Notify can do, Realtime can do better.
Sequin
We felt there was a gap in the option space for Supabase, which is why we built Sequin.
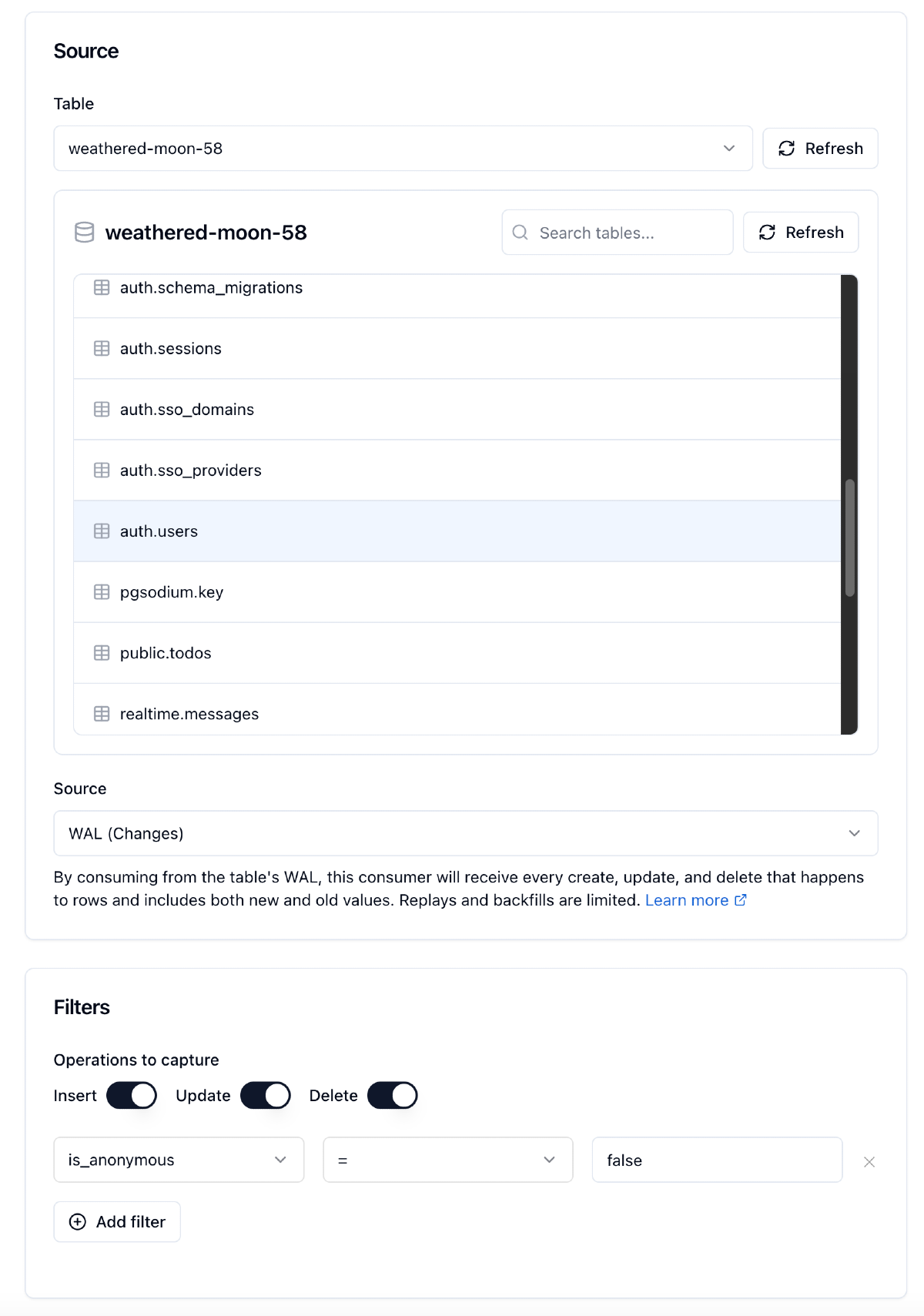
Sequin is an open source tool that pairs nicely with Supabase. Unlike Database Webhooks or Realtime broadcasts, Sequin is designed to deliver webhooks with exactly-once processing guarantees. After connecting Sequin to your Supabase database, you select which table you want to monitor and filter down to which changes you care about:
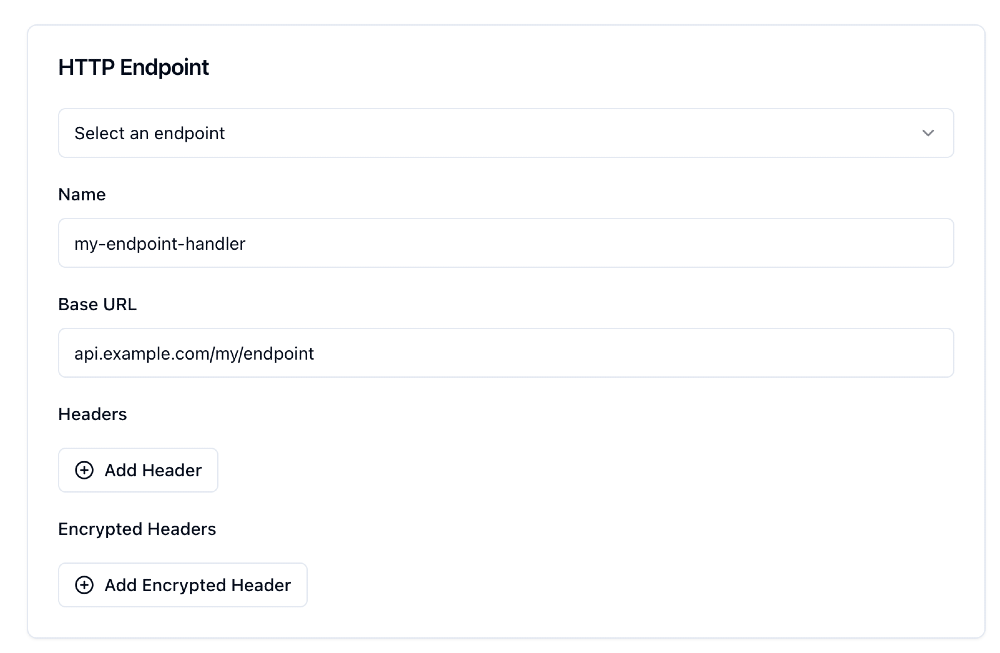
You then tell Sequin where to send change event webhooks:
Unlike Database Webhooks, if your servers are down or your functions return errors, Sequin will keep retrying the message (with backoffs). So you get retries, replays, and a great debugger experience.
Sequin comes as a cloud offering so it's easy to get up and running.
When is Sequin not a good fit?
For really simple use cases that a 5-line PL/pgSQL trigger can handle, Sequin is probably too heavyweight. Same if your Database Webhook is fire-and-forget – you won't need Sequin's delivery guarantees.
Sequin's also not a good fit for pub/sub use cases like Realtime. Because Sequin offers exactly-once processing, it only delivers messages to a single worker at a time.
Choosing the right approach
To recap, here's when you might consider each approach:
Triggers are great for maintaining order and consistency in your database. Ideally, your triggers are not too complicated and you don't have too many of them. If your table has high write volume, be mindful of them.
Database Webhooks are good for quick fire-and-forget use cases. Things like POST'ing a Slack notification for your team or sending an analytic event.
Realtime can help you build a differentiating client experience. You can use it to build a reactive client that updates immediately when data changes in the database. Or power features like presence in collaborative editing tools. You can also use Realtime where you might otherwise reach for a pub/sub system like Simple Notification Service (SNS) to broadcast events to backend services that you're OK with missing some events.
Sequin lets you write robust event-driven workflows with exactly-once processing guarantees. It's a more powerful and easier to work with version of Database Webhooks. It's great for critical workflows like sending emails, updating user data in your CRM, invalidating caches, and syncing data. You can even use Sequin in place of a queuing system like SQS or Kafka.