

We're building Sequin, a Postgres CDC tool to streams and queues like Kafka, SQS, HTTP endpoints, and more. Efficient, correct pagination is paramount for our backfill process, so we use keyset cursors extensively.
You've probably heard about the limitations of offset/limit in Postgres. There are two primary concerns with this strategy:
- Performance
- Correctness (skipping rows)
A better alternative in most situations is keyset pagination. Keyset pagination solves performance issues. It promises tight correctness guarantees (with some caveats, which I'll get into). And it can often lead to a better UX.
The appeal of offset/limit
It's easy to understand why offset pagination is so widespread. The implementation is straightforward:
select * from users
order by created_at desc
limit 20 offset 980;
Building an API interface on top of offset pagination is simple too:
{
"items": [...],
"page": 50,
"per_page": 20
}
Offset pagination is a fine way to get started, but has performance limitations and correctness issues:
Performance drawbacks
The root of offset's performance problem lies in how Postgres handles offset queries. When you request rows with an offset of 1000, Postgres must still traverse those first 1000 rows in the index, even though they'll be discarded. This means that as users go deeper into the result set, query time increases linearly:
-- Page 1 (fast)
select * from large_table order by id limit 20 offset 0;
Time: 468 us
-- Page 50 (slower)
select * from large_table order by id limit 20 offset 1000;
Time: 1 ms
-- Page 500
select * from large_table order by id limit 20 offset 10000;
Time: 3 ms
-- Page 5000
select * from large_table order by id limit 20 offset 100000;
Time: 19 ms
-- Page 50000
select * from large_table order by id limit 20 offset 1000000;
Time: 87 ms
It doesn't matter if you have an index on your sort column. While an index can help Postgres find a starting point quickly, it still needs to walk through the index to count off the offset rows. The operation is still O(n).
Correctness problems
Performance aside, offset pagination has a correctness problem, specifically with tables where rows can be deleted. Consider this sequence of events for offset pagination that powers a UI:
- User requests page 1, gets rows 1-20.
- Row 1 is deleted.
- User requests page 2.
- The row that was previously at position 21 is now at position 20, so now belongs to page 1. It will not appear in the result set for page 2.
- The user never sees the row that moved from 21 to 20.
If you don't delete records from your tables, offset pagination is as correct as keyset pagination (with the same caveats, covered below). Except, as you'll see, you have fewer tools for fixing corner cases.
Keyset pagination
Instead of counting offsets, keyset pagination uses a compound cursor. Here's what that looks like:
select * from users
where (updated_at, id) > ('2025-01-01', 123)
order by updated_at asc, id asc
limit 20;
It's called keyset pagination because the comparison is a set of keys (i.e. (updated_at, id)).
Compound cursor
Using a compound cursor allows you to produce a "total order" of your table. This means these properties:
- Every row has a unique position in the sort order
- The position of a row only changes if the sort field of the row is modified
- Insertions and deletions of other rows don't affect the relative ordering
You can sort and traverse by a single column, but it must be unique. updated_at is not safe to use on its own, as many rows can have the same updated_at value. If 1000 rows all have the same updated_at value and your page size is 100, there is no way for you to traverse the rows safely.
Traversing
To traverse a table using keyset pagination, you'll need to keep track of the last row's cursor values from your previous query. Here's how it works:
- Initial query (first page):
select * from users
order by updated_at desc, id desc
limit 20;
- Subsequent pages (going forward):
select * from users
where (updated_at, id) < (last_updated_at, last_id)
order by updated_at desc, id desc
limit 20;
- Going backward:
select * from users
where (updated_at, id) > (first_updated_at, first_id)
order by updated_at asc, id asc
limit 20;
The key is to always include all columns in both the where clause and the order by.
See below for how to wrap an HTTP API around this.
Handling deletions and modifications
Keyset pagination handles deletions gracefully.
However, if a row's sort key changes, the row might appear twice or be skipped.
If a row's sort key can only be incremented (e.g. updated_at), it may appear twice over the course of pagination. It might be read once early on, then "bumped up" to the top of the table, and read again near the end.
If you're doing a one-time sweep of a table and want to avoid seeing a row twice, one easy solution is to start your pagination by first grabbing a max keyset cursor:
select updated_at, id
from users
order by updated_at desc, id desc
limit 1;
Then, you can paginate from the beginning of the table up to the max, as opposed to the end of the table. (This will, of course, mean your process will miss all inserts and updates that happened during pagination.)
If a row's sort key can be decremented (like priority fields or scores), it may be skipped during pagination. However, these kinds of sort columns are uncommon to use for traversal.
Designing interfaces around keyset pagination
Keyset pagination doesn't have the same concept of pages that offset/limit does. Showing the classic pagination component doesn't really make sense:

With offset/limit, the link for "7" maps to offset = (page_size * (7 - 1)). But with keyset pagination, we don't have this concept.
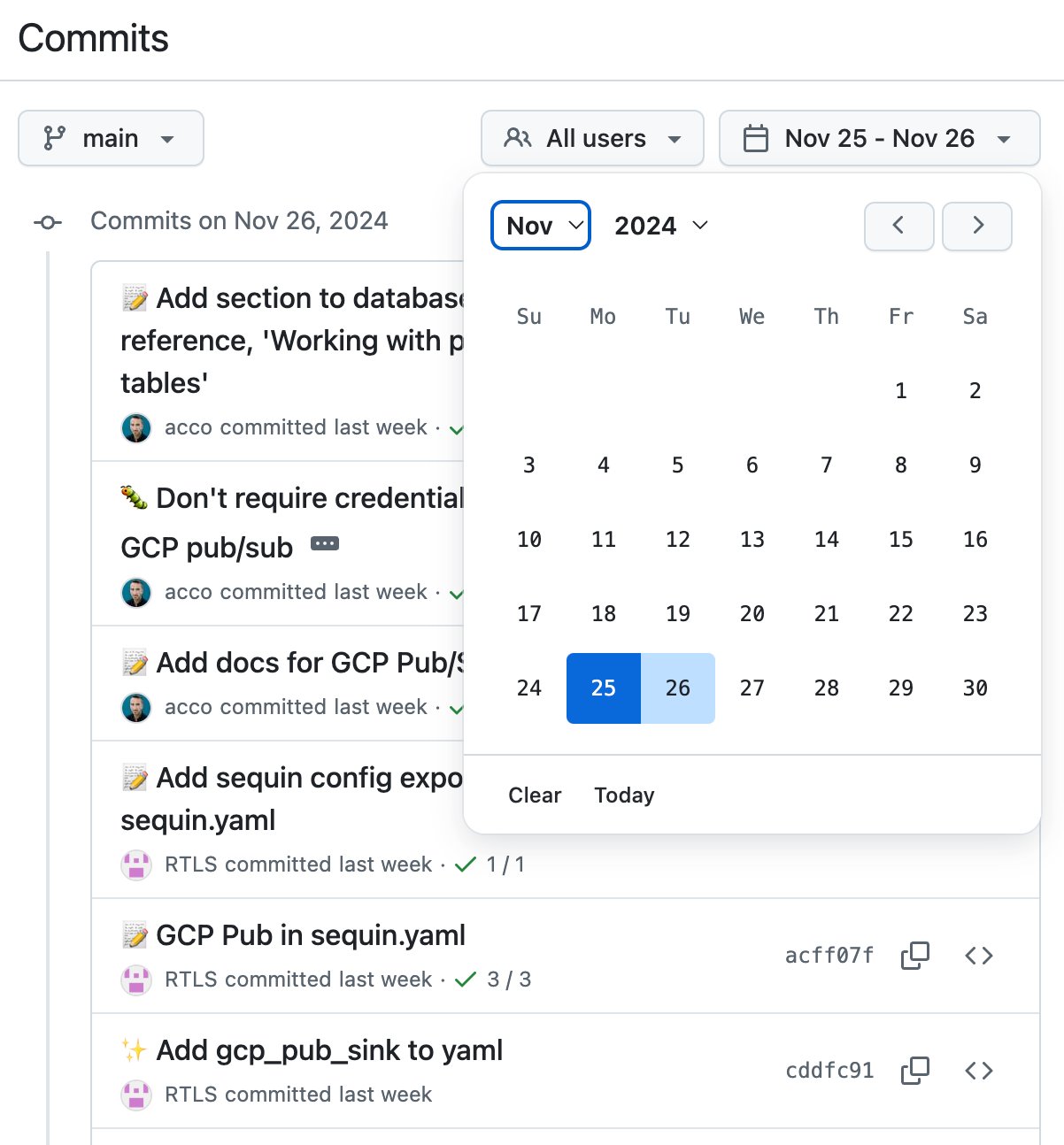
Consider GitHub's commit view for a repo. Commits are shown sorted by committed_at desc. At the top is a date range selector for filtering commits down:
And at the bottom are "Previous" and "Next" links:
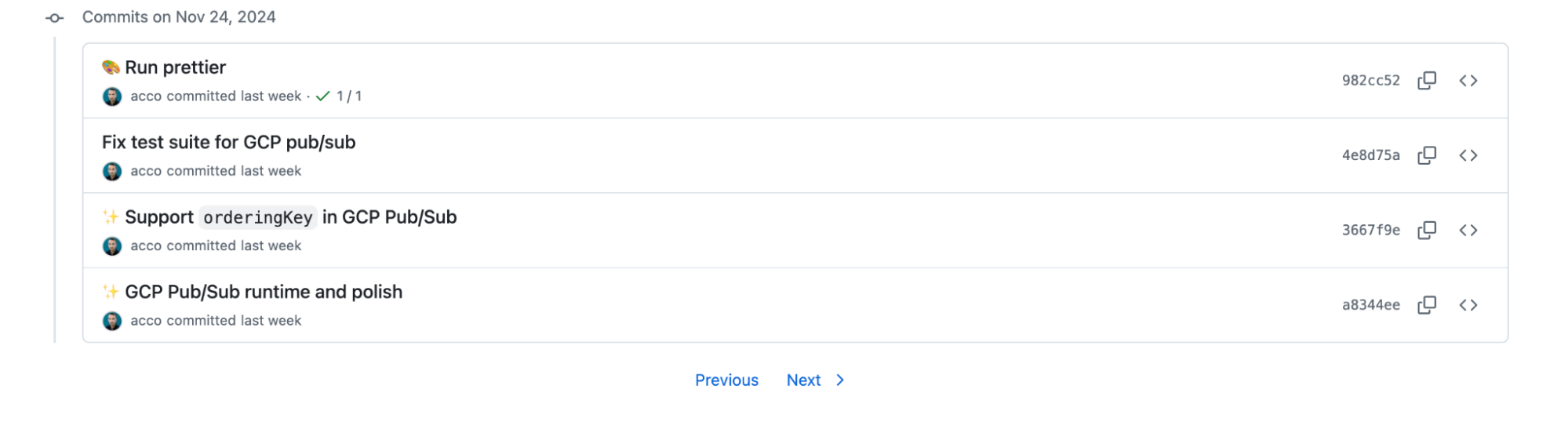
There is no pagination component. This is because GitHub uses keyset pagination everywhere.
This user experience is mostly good, as users typically care about domain-level filtering (commits between these time ranges) versus the arbitrary traversal of pages. You aren't coming to the commits page to find commits that happened "30 pages ago," you have date ranges in mind.
One improvement I'd make to GitHub's UX: while jumping forwards and backwards by pages rarely makes sense, jumping forwards and backwards by relative time certainly does. This interface would be improved if they had forward and backward links for 1d, 7d, 1mo, etc. Selecting time ranges is a little slower. Relative times would allow for quick traversal, and would be superior to pages in every way.
Consider this pattern in your own implementation.
Designing APIs around keyset pagination
To build keyset pagination into your HTTP API, you can simply base64 encode a data structure that contains values for each key.
Your keyset cursor will likely consist of primary keys and a timestamp field, like updated_at. One encouragement I have is to have a mechanism for a user to fetch a page with only the sort key (e.g. updated_at) without including primary keys. This is necessary for them to get a starting position.
For example, they may want to grab all items from the last 30 days. To begin their traversal mid-table, they will want to make their first request with query params equivalent to updated_at > now() - 'interval 30 days' order by updated_at asc. Then, from there, they can use the cursor in your response to safely continue their pagination.
Traversing forwards and backwards
There are many ways to allow users to traverse an HTTP API in one direction. Things can get complicated, though, if you want to let users arbitrarily reverse direction and start traversing the other way.
Some APIs opt for returning nextPage and previousPage tokens. I think this works if the page embeds the limit as well (which these same APIs rarely do). A page implies a limit. So this can work if after the initial request, you drop params like limit and order and move to using nextPage and previousPage to traverse.
You might be tempted to simply return a cursor, which is just the keyset values of the last item returned. Then users can pass in after={cursor} or before={cursor}. But this only makes changing directions more confusing: if they switch directions, aren't you just going to return the exact items in the next response? And don't they need to change the order param too?
So, I think it's reasonable to return cursors that traverse in just one direction. In fact, you can consider embedding the order param in the cursor itself. The cursor can embed all the information needed to grab the next page of this chain, save for perhaps the limit. You can even enforce this mental model by rejecting query params like order in follow-up requests.
If users want to reverse, they can grab a record from the last response and use that to construct the initial query for going the other direction. One nice interface for this is allowing for a param like after={id}. Your system will grab that record, construct a keyset cursor from its fields, fetch the page, and return the page with the next keyset cursor to use.
Correctness issues with keyset pagination
As I've written about previously, stable ordering in Postgres breaks down at the tail (around recently committed rows). There are no locks on Postgres sequences, so Postgres sequences can commit out-of-order. And timestamps are no better; when setting updated_at to now(), you can have a row with an older timestamp commit after a row with a newer timestamp.
This means it's possible for keyset pagination to skip rows. The first query might return a page that looks like this:
Result:
id | user_name | inserted_at ∇
---+-----------+------------------------
4 | Paul | 2024-08-19 10:00:00
2 | Irina | 2024-08-19 09:59:58
1 | Feyd | 2024-08-19 09:59:00
But if you were to query right afterwards, you'd get a result like this:
id | user_name | inserted_at ∇
---+-----------+------------------------
4 | Paul | 2024-08-19 10:00:00
3 | Duncan | 2024-08-19 09:59:59
2 | Irina | 2024-08-19 09:59:58
Note how "Duncan" popped into the second position. With keyset pagination, you'd completely miss this record!
This problem has plagued almost every HTTP API I've ever worked with.
In the blog post above, I discuss options for mitigating. There isn't a clean silver bullet here. So if you need stable keyset pagination at the tail, you'll need to pick the option that best fits your requirements.
Which pagination strategy should you use?
Use keyset pagination when:
- You have a large dataset
- Performance is important
- You need stable ordering with deletions
- Your UI can work with "Previous/Next" navigation
- You have a natural sort order (like timestamps)
While offset/limit is slightly faster to get started with, in most modern applications keyset pagination is the better choice. The performance benefits alone usually outweigh the slightly more complex implementation. The improved correctness guarantees and better handling of deletions make it even more compelling.