
Database replication is critical for modern applications. Teams build replication pipelines for data synchronization, building event-based workflows, or improving availability.
At Sequin, we set out to build a very fast replication pipeline with strong delivery and ordering guarantees. After several iterations, we want to share where we landed.
In this post, we'll explore how Postgres replication works under the hood and detail the architecture behind Sequin.
Beyond helping you understand Sequin's approach, these concepts should prove valuable if you're building your own data pipelines, implementing change data capture systems, or simply want to better understand the challenges of maintaining consistency in distributed systems.
Postgres replication
In Postgres' logical replication protocol, Postgres pushes change messages from the server (Postgres) to the client (e.g. Sequin). Changes stream serially, in order.
Only one client can be connected to a replication slot at a time. Postgres streams the client messages as fast as it can. Each message pertains to a change (e.g. an insert, update, or delete) or metadata about the database (e.g. a message describing a table and its columns).
Each message is associated to a log sequence number or LSN. An LSN refers to a position (offset) in Postgres' write-ahead log. [1]
Successful delivery of a message to the client does not mean the message is now durable, however. The client may have some async processing to do before committing messages. If you're building a database replica, you might for example batch rows in-memory before flushing them to disk. For Sequin, messages are buffered in our system for a period after Sequin receives them from Postgres but before Sequin delivers them to downstream sinks.
So, the client is expected to tell the server what its confirmed flush LSN is on occasion. That indicates to the server which messages the client has fully processed. The server can then increment the corresponding confirmed_flush_lsn cursor of the replication slot.
Incrementing the confirmed_flush_lsn cursor has two effects:
- If the replication connection is restarted, when the connection is re-established, Postgres will begin playing messages from that point forward. So the client will want to advance the
confirmed_flush_lsnregularly to avoid replaying the same messages over and over. - Postgres will hang on to messages that have not been flushed to all clients indefinitely. So if the client does not advance the
confirmed_flush_lsn, the server’s replication slot would consume storage indefinitely–not good!
How Sequin processes Postgres replication messages
Postgres' replication protocol provides a solid foundation for change data capture, but there are several challenges when implementing a production pipeline:
- Storage management: If a client can't keep up with the stream, Postgres will store messages indefinitely, potentially causing disk usage to balloon on your database server.
- Delivery guarantees: The client needs to ensure it doesn't lose messages if it crashes or disconnects from Postgres unexpectedly.
- Ordering: While Postgres guarantees serial delivery of changes, maintaining this ordering when processing messages in parallel requires thoughtful design.
We wanted to build Sequin to address these challenges while keeping the system simple to operate. Here's how we approached it at a high-level:
- Sequin reads messages in from the replication slot. Those messages are buffered in-memory. Importantly, the system does not advance the
confirmed_flush_lsnin the replication slot right away. - Sequin attempts to deliver those messages. In the happy case, all messages are written to the destination.
- Sequin writes failed messages to an internal Postgres table. In the unhappy case, some messages fail to deliver. Sequin persists those messages to an internal Postgres table. Sequin attempts to re-deliver them indefinitely.
- Sequin advances
confirmed_flush_lsnon an interval. With our approach, messages are either delivered or written to Sequin’s internal Postgres table soon after they enter the system. So, given that messages are persisted either upstream or in Sequin, it's safe to advance theconfirmed_flush_lsnand allow Postgres to remove replication slot messages.
Let’s step through each of these:
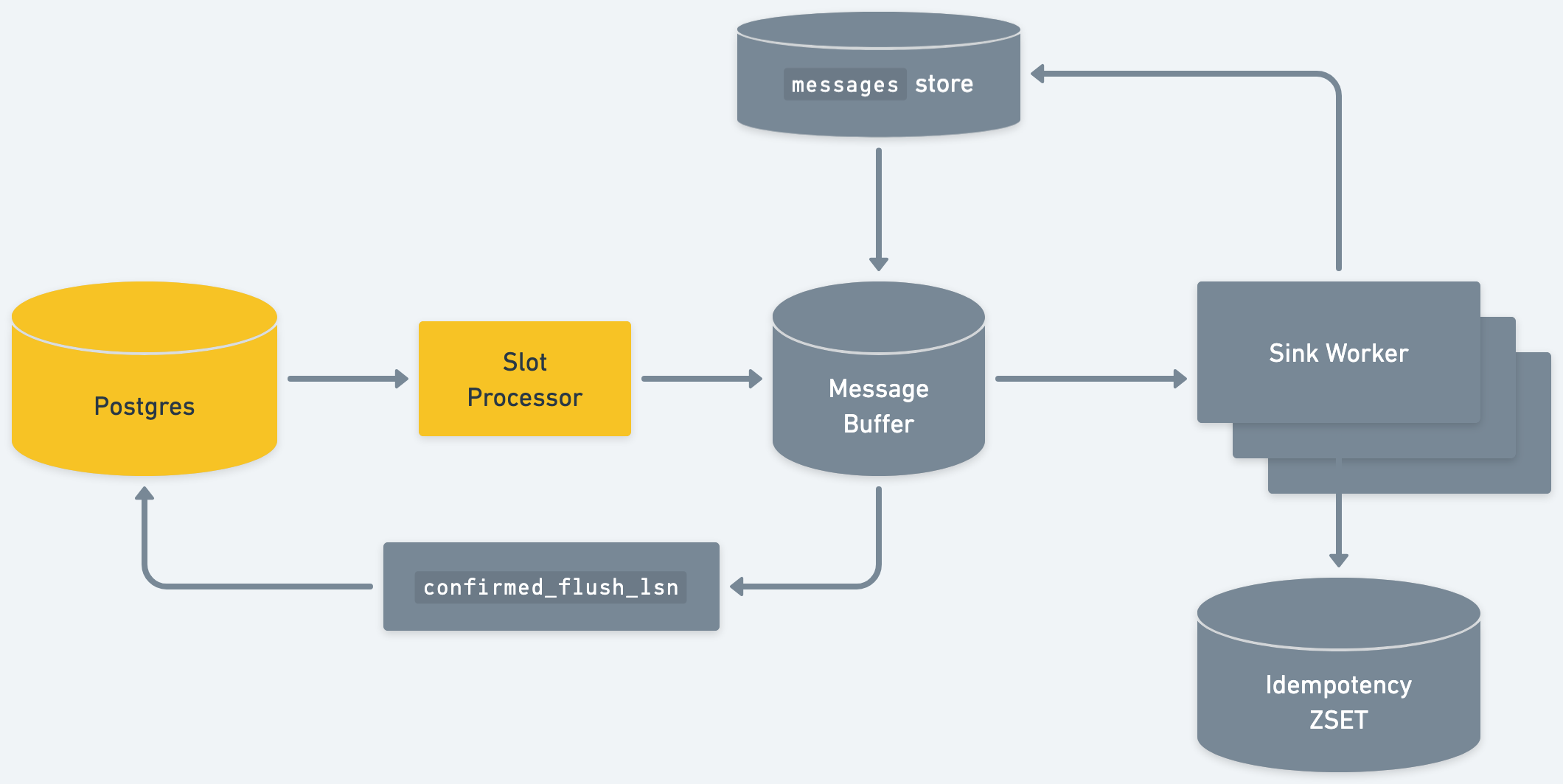
Step 1: Reading in messages
After connecting to Postgres using Postgres’ standard TCP handshake, Sequin initiates the replication connection. Postgres begins sending replication messages. Postgres begins sending messages from confirmed_flush_lsn forward.
Sequin parses these messages and routes them to buffers for each sink. The sink buffers contain an ordered list of all messages that are pending delivery:
Step 2: Delivering messages
For each sink, Sequin has a pool of workers that deliver messages. However, the system can’t simply pop messages from the buffer using a simple first-in-first-out algorithm.
Sequin guarantees that messages that belong to the same group are delivered in order. By default, messages are grouped by primary key(s). So, changes that pertain to the same row (same primary key(s)) will be delivered to the sink in order.
The outgoing message buffer maintains a set of all primary keys that are out for delivery. Let’s call this set inflight_primary_keys. The algorithm for popping a message for delivery looks like this:
- N = 0
- From the sorted list of messages, check the message at position N.
- Check if the primary keys of the candidate message exist in
inflight_primary_keys - If not, deliver the message. Add its primary keys to
inflight_primary_keys - If so, skip the message. Increment N = N + 1 and repeat
Because the messages are sorted and inflight_primary_keys is a set, the popping algorithm is fast.
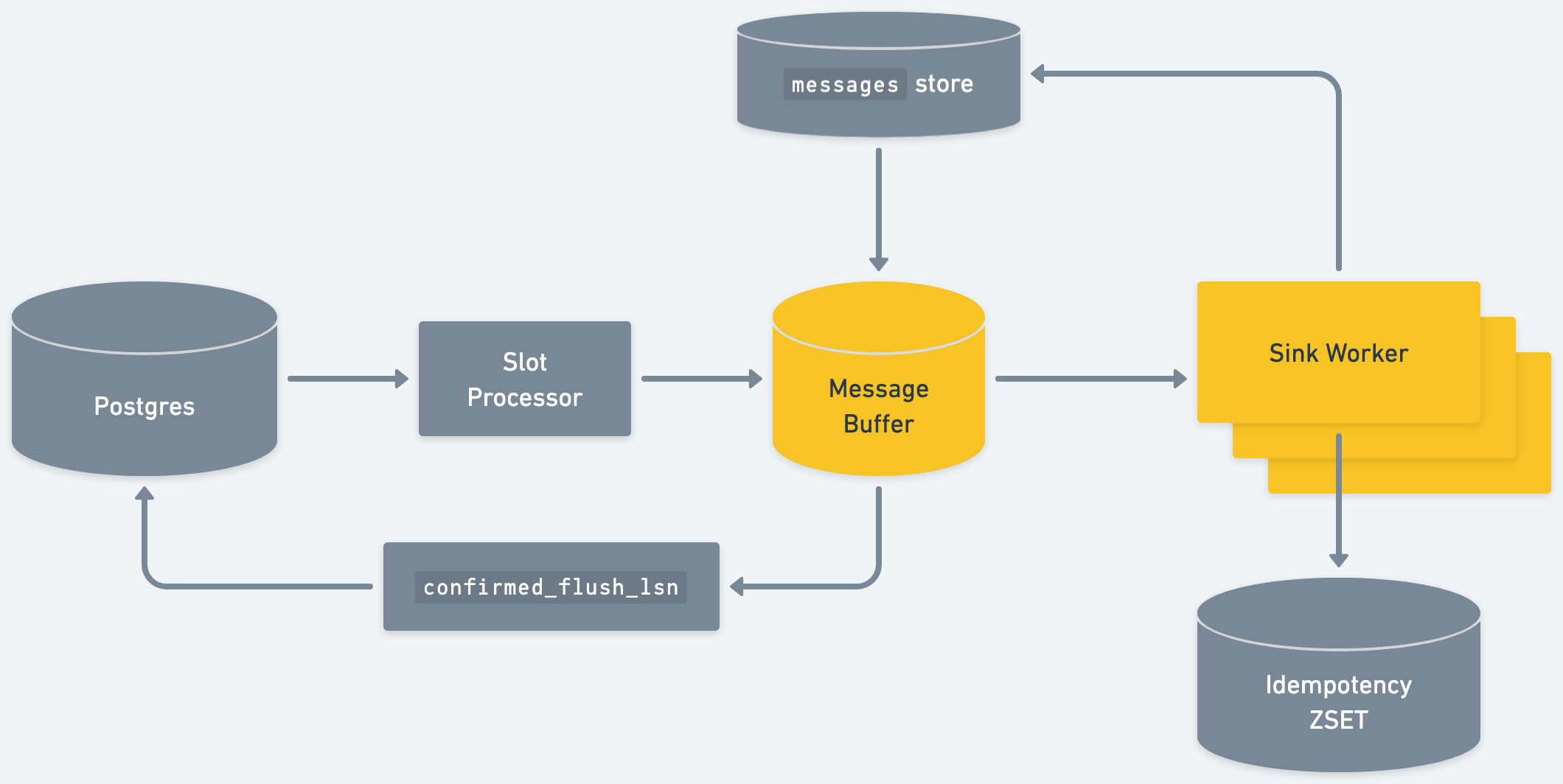
Step 3: Failed messages
In the happy path, messages never touch disk. They’re shuttled from the source replication slot straight to the destination sink.
When a message fails to deliver, Sequin writes the message to an internal Postgres table, messages. The message is retried with an exponential back-off. Sequin’s message popping algorithm contains an additional step where we check if any failed messages are ready for redelivery.
The messages table contains metadata about the delivery failures, like the count of attempts and errors that the system has received. These are updated after every failed delivery, so Sequin’s exponential backoffs persist across restarts.
This means failed messages incur a small performance penalty on a sink. But the penalty is capped. When a sink maxes out its failed message limit, the sink will stop accepting new messages until failed messages begin clearing. This provides healthy back-pressure on the system when a high volume of messages are not delivering.
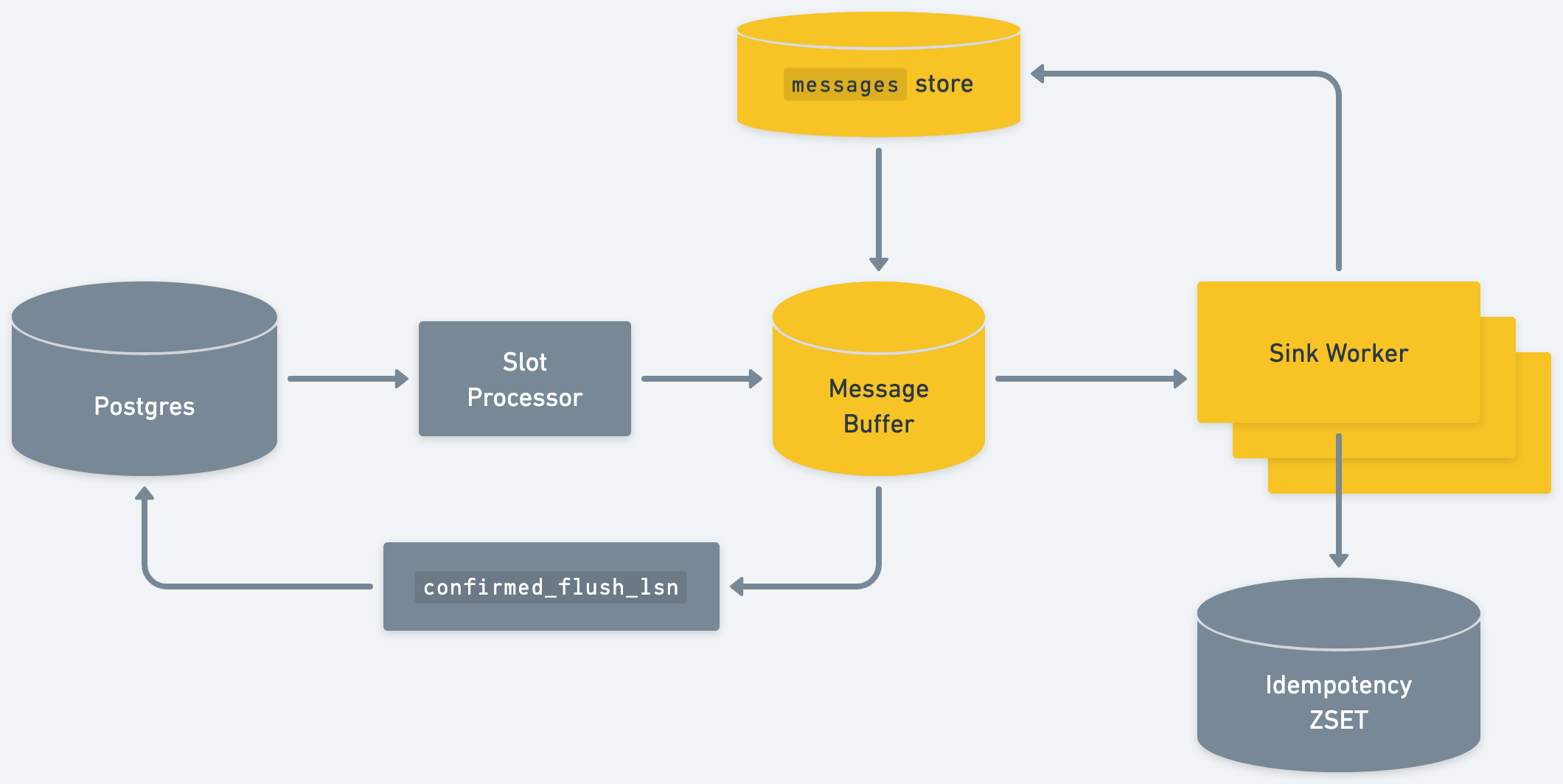
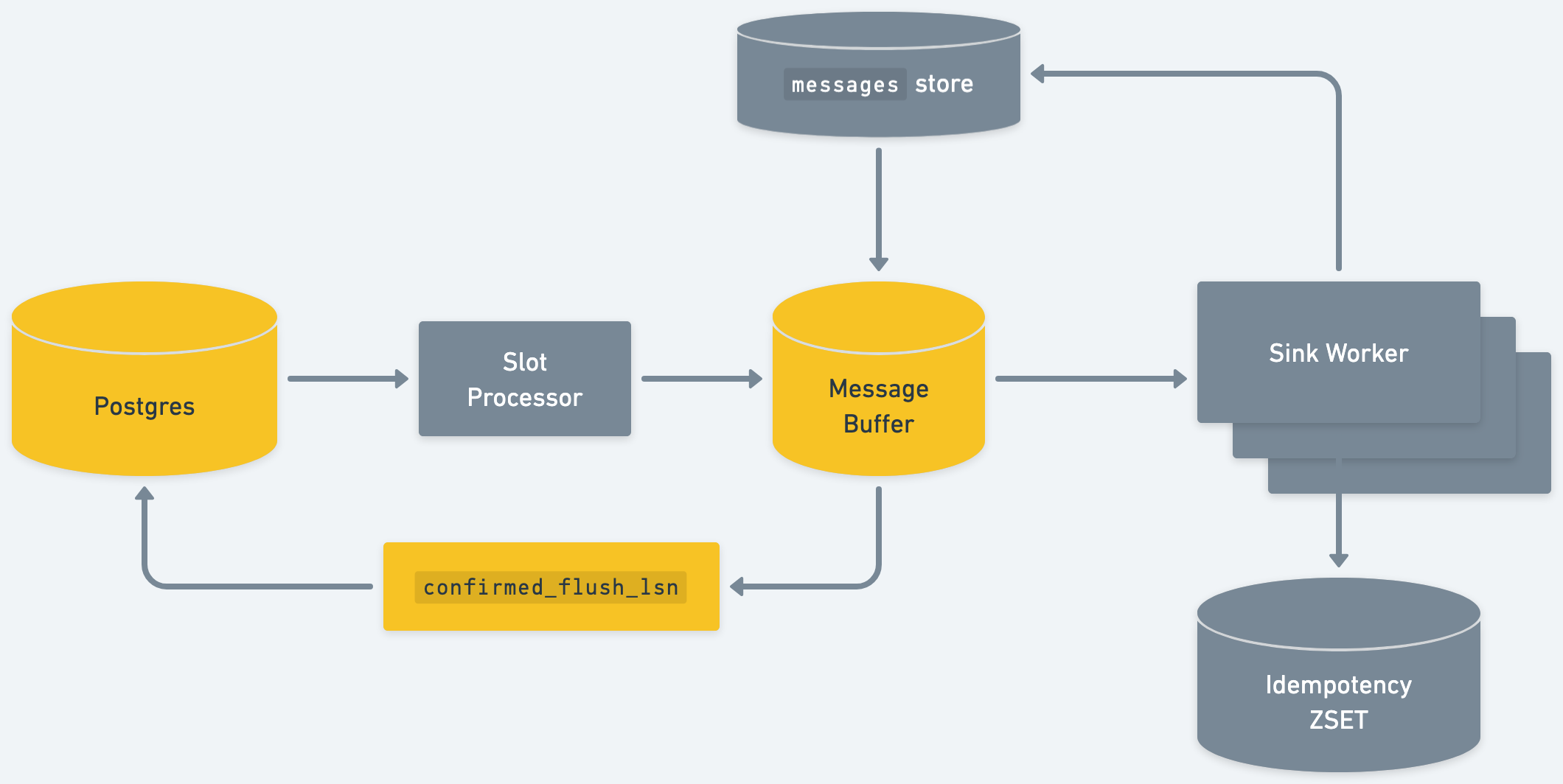
Step 4: Updating confirmed_flush_lsn
This design means messages will only be in memory for a short period of time. A message will either be delivered to the downstream sink or written to the messages table. [2]
Therefore, we can regularly update the confirmed_flush_lsn. On an interval, the system looks across syncs and sees what the minimum “unflushed” LSN is across sinks. A message is “unflushed” if it’s in-memory only. We send the updated LSN to the Postgres replication slot, which allows Postgres to advance the cursor:
Idempotency
The design discussed so far offers at-least-once delivery guarantees. Because messages need to be either delivered or persisted in Sequin’s internal Postgres before we advance the LSN of the replication slot, no messages will be missed.
However, it would result in a lot of duplicate deliveries. That’s because whenever the connection to Postgres is restarted, Postgres will replay messages from the last LSN we flushed. And in most cases, we’ll have already delivered some of the messages after that LSN.
We wanted our system to get as close to exactly-once delivery as possible.
To do so, we use a Redis set “at the leaf.” Right before delivering a batch of messages, a sink delivery worker checks a Redis sorted set to see if any of its messages were already delivered. It discards any that were. Then, after delivery, the worker adds the message’s unique key to the sorted set, protecting against future redeliveries:
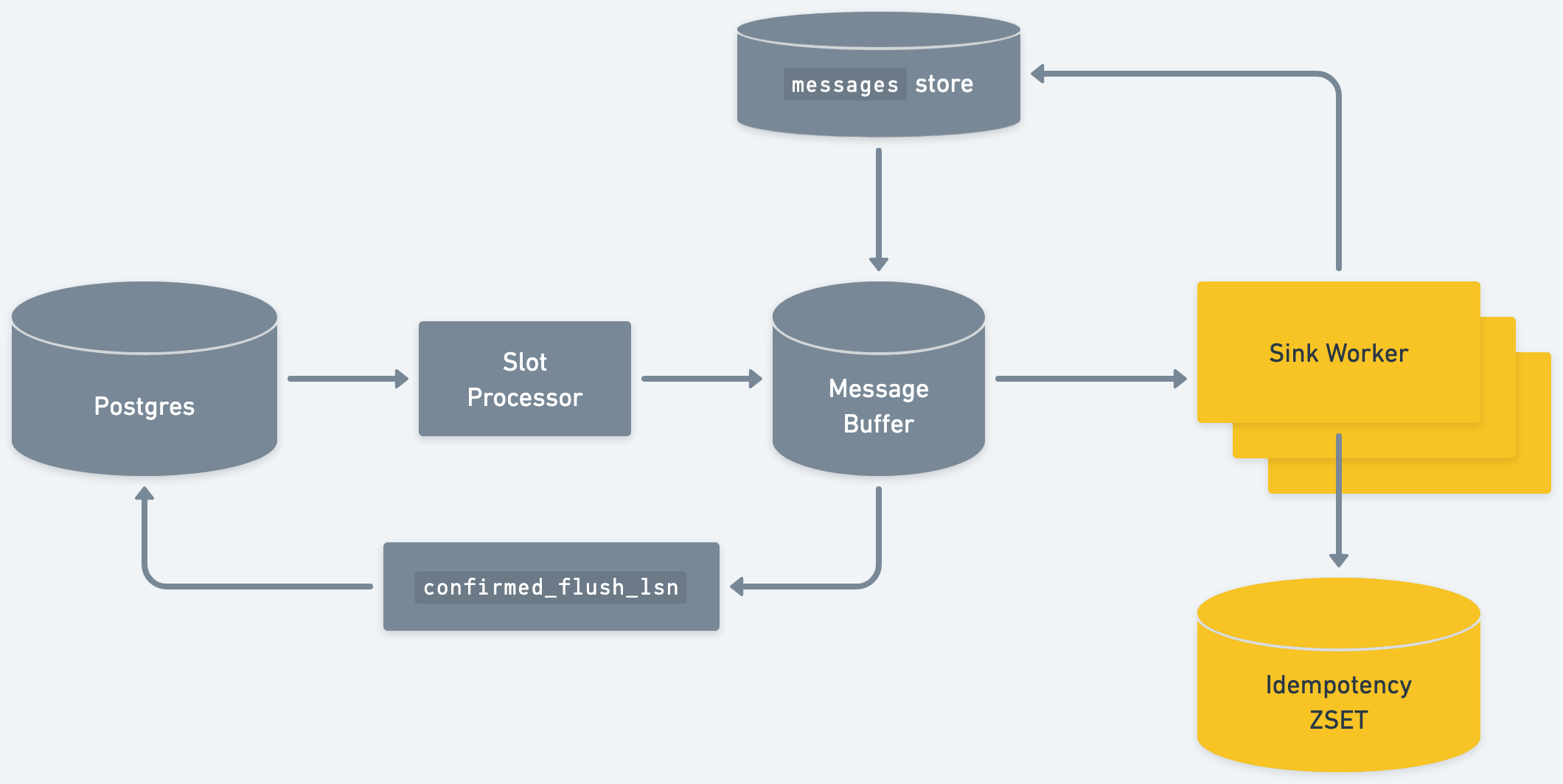
With just this strategy alone, the sorted set would grow unbounded. So, the system regularly trims the set. It’s safe to trim the set by LSN: we can safely remove all messages that are below the LSN of Postgres’ replication slot, as Postgres will never deliver them to us again.
Partitioning
With the right data structures, this data pipeline can move fast. As long as only one worker can pop from the message buffer at a time, it’s safe to run many delivery workers concurrently. This is where you want most of the concurrency, as these workers do I/O (network calls to the sink destination).
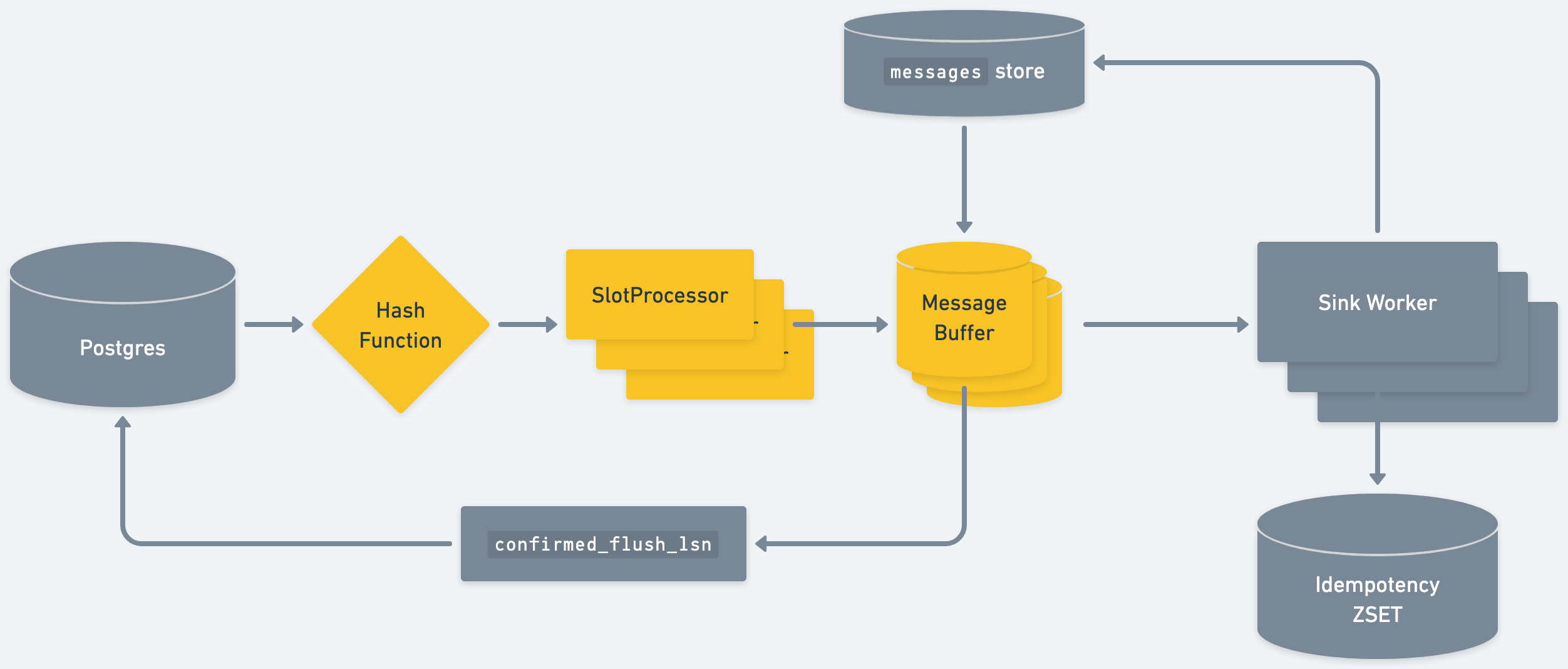
However, we wanted to build a system with the maximum throughput possible. To get there, we need to make as much of our data pipeline parallel as we can. Our goal is to evenly saturate all CPU cores on a machine.
To do so, we partition messages by primary key shortly after they enter the system. There’s a single process that manages the TCP connection with Postgres. As it receives messages, it does the minimum amount of processing possible. Once we have the message’s primary keys, we can route it via a consistent hash function to one of several instances of our data pipeline. This maintains order for messages pertaining to a given set of primary key(s):
Conclusion
Sequin is designed from the ground up to be fast, while offering delivery and ordering guarantees.
The system doesn’t need to store in-flight messages to disk–Postgres is already storing messages for us in the replication slot. However, our in-memory design requires some thoughtful orchestration between a few moving parts, such as the sinks, an internal messages table, and the replication slot’s confirmed_flush_lsn.
We also had to iterate on data structures to maximize throughput. Our in-memory message buffer is accompanied by 4 other data structures that assist with indexed lookups and other derived states.
The result is a system that transparently handles the complexity of replication, giving developers a simple, reliable interface to stream changes from Postgres to wherever they need to go. Check out our quickstart to give it a try!
Technically, transactions are associated with an LSN – the LSN of the commit of the transaction. And messages are associated with a transaction. Messages don’t have their own unique LSNs or any other unique identifier. However, you can derive a unique identifier for a message by creating a two-element tuple: the first element of the tuple is the LSN of the transaction, and the second element is the index of the message inside the transaction. (Message ordering within a transaction is stable.) ↩︎
The design discussed above doesn’t account for a couple corner cases that our system accounts for. For example, when Sequin is failing to deliver a message for a row, subsequent messages for that same row will be blocked indefinitely. We don’t want those messages to hang out in-memory, as then we can’t advance the LSN. So Sequin writes blocked messages to the
messagestable. ↩︎