

In change data capture, consistency is paramount. A single missing or duplicate message can cascade into time-consuming bugs and erode trust in your entire system. The moment you find a record missing in the destination, you have to wonder: is this the only one? How many others are there?
Sequin sends changes from Postgres to destinations like Kafka, SQS, and webhook endpoints in real-time. In addition to change data capture, we let you perform table state capture: you can have Sequin generate read messages for all the rows or a subset of rows from tables in your database. This lets you rematerialize all your Postgres data in your destination. Or recover from errors by replaying Postgres rows through your system.
Because Postgres does not keep its WAL around indefinitely, we can't use the WAL to do a full table state capture. The WAL is only a partial tail of recent changes in the database. It's intended to send the latest changes to replicas.
Instead, we can perform table state capture by reading from the table, such as running a select.
Performing table state capture at the same time as you're capturing changes, though, turns out to be quite nuanced. That's because the table you're capturing is constantly changing as you're capturing it.
To get an idea of the challenge, imagine an implementation where we run the change data capture process at the same time as the table state capture process. Let's call the change data capture process the SlotProcessor and the table state capture process the TableReader.
Let's say we have some row, A₀. (The "0" represents the version of row A.) Before TableReader starts, row A is updated a few times:
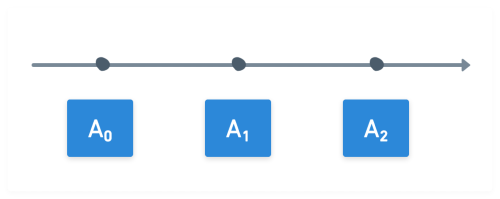
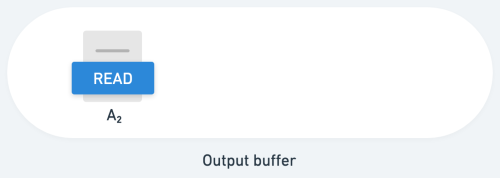
Then, you start TableReader. TableReader captures A2 (the current version of A) and inserts it into the outgoing message buffer. (The output buffer is the outbox between Sequin and sinks.) We say that TableReader has emitted a read message for A2:
While this happened, SlotProcessor had fallen behind. So, it first picks up the change message for A0 to A1. Then the change message for A1 to A2.
This leads to an unfortunate ordering of messages in our output buffer:
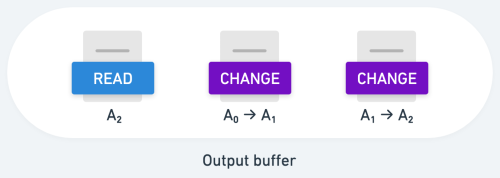
This is undesirable, and could lead to many downstream problems.
But an even worse race condition can occur: it's possible that when TableReader queries, it will see A1. Then A1 is modified, becoming A2. The SlotProcessor picks up the A1 to A2 transition first. Then TableReader's query makes it to the output buffer:

Now, unsuspecting downstream consumers will presume A1 is the final version of A – but it's not!
Row A is stale in your stream, and there's no hope of recovering it until it's updated again.
At a high level, what's happening is that we have two streams of data, the stream from the table and the stream from the replication slot. Both those streams correspond to the same, ever-changing source. And we have no coordination between those two streams.
In order to achieve consistency (i.e. a consistently-ordered output buffer), we need some coordination between these two streams.
Let's build up to a consistent strategy for running both capture processes in parallel. By examining each potential solution, we'll uncover the subtle pitfalls that led Sequin to adopt its coordination strategy.
Solution A: Serialize capture processes
A simple solution is to not run change capture and table state capture at the same time:
- Create the replication slot. We do this before we capture the table. That way, SlotProcessor can accumulate changes that happen during the table capture.
- Run TableReader's full capture process. TableReader can write directly to the output stream.
- Once TableReader is done, we can apply the SlotProcessor's accumulated changes.
This approach can work because we're only processing one stream of data at a time. That means we need to do little coordination between them.
There's a path to making this approach consistent. But the drawback of this approach is that it isn't very flexible. We have to stop change capture in order to capture the table, which might take some time.
In operational use cases (like streaming to Kafka or SQS), you might run table captures often. For example, you might realize you deployed a bug and a downstream system needs to have the last few hours of data replayed. You don't want to stall change processing during that replay, which this design requires.
Solution B: Pipe table capture through the replication slot
As a thought exercise, another solution is to run our table capture process through the WAL. By having everything funnel through the WAL, we'll get strict ordering guarantees. That's because by forcing table capture through the change capture stream, we only have one stream to process.
The most naive solution is to simply touch every row:
update mytable set id = id;
Of course, this strategy has a lot of undesirable side effects, not the least of which is adding a ton of load to the database.
Solution C: Buffer the entire table capture process
The purpose of the table capture process is to load all selected rows into the destination. It's worth noting that if a row happens to get modified during the table capture process, it's actually safe for TableReader to skip that row. We don't need to emit a read message for the row in the table capture process, as the change capture process will emit an insert or update message for it.
Given that, another consistent solution follows this process:
- Start the SlotProcessor.
- Start the TableReader. Store all rows in memory.
- While the TableReader is running, the SlotProcessor keeps track of all records that it has seen (by primary key).
- When the TableReader finishes, it emits a WAL message:
SELECT pg_logical_emit_message(true, 'my-cdc', '{"backfill_id": 1, "marker": "end"');
pg_logical_emit_message is a neat function that lets you write a message directly to the WAL. This message is how we "join" the two streams. When the SlotProcessor sees this message, it can briefly halt WAL processing. Then, it can emit TableReader's buffer into the output stream. Importantly, it first filters out every row in the set whose primary key ever appeared in the WAL processor.
This approach is consistent: we no longer need to worry about how we order our read messages and change messages. However, it's suboptimal, as the TableReader's buffer would grow very large with a large table.
But this design reveals a path: we can use a strategy where TableReader builds up its rows in memory. And SlotProcessor can then filter that set and insert it into the output stream.
Solution D: Buffer chunks of table capture
Having TableReader build up all its rows in memory is suboptimal. But what if we chunked it? That tweak brings us close to Sequin's design.
A few years ago, Netflix released a whitepaper on the design of their internal change data capture tool, DBLog. Sequin's table capture design is in part inspired by DBLog.
The TableReader process can build up smaller chunks of rows in memory. Then, SlotProcessor can filter them against recent changes that came through the WAL before inserting read messages into the output stream.
What that looks like at a high level:
- Run TableReader. It accumulates e.g. 100k rows in memory.
- While TableReader is selecting its chunk, SlotProcessor is tracking which PKs have flowed through the logs.
- When TableReader fills out its chunk, it emits a
chunk-endmessage. - SlotProcessor sees the
chunk-endmessage come through the slot. It can then fetch the chunk, filter it, and insert the chunk into the output stream. - After inserting the chunk, the SlotProcessor can flush all the primary keys it was holding in memory.
This solution works great. But we're missing some coordination: when should the SlotProcessor start accumulating primary keys? We don't want it to indefinitely accumulate primary keys.
DBLog uses the watermark pattern here: TableReader can emit a low watermark before its first select query. That serves as a signal to SlotProcessor: "I'm about to run a select query to grab a chunk of rows. Start keeping track of which primary keys have come through the slot for later filtering."
The low watermark should include a table OID so that SlotProcessor only hangs on to primary keys for that table:
SELECT pg_logical_emit_message(true, 'my-cdc:low-watermark', '{"backfill_id": 1, "table_oid": 1234');
So, TableReader:
- Emits a chunk capture low watermark
- Runs a select to buffer its chunk
- Emits a chunk capture high watermark
And SlotProcessor:
- Receives the low watermark. Now it knows to start accumulating primary keys for that table.
- Processes the replication slot per usual.
- Receives the high watermark. Now, it can retrieve TableReader's chunk, filter it by primary key, and emit messages to the output stream.
After TableReader's chunk is written to the output stream, TableReader can flush its chunk and SlotProcessor can flush its primary keys.
Comparison to DBLog
The process we landed on is very similar to how DBLog works.
One difference is that DBLog uses a watermark table to produce its messages. DBLog inserts low and high watermarks into a table. That then produces a WAL message for SlotProcessor to later capture.
This strategy is nice because it's applicable to more databases (vs using pg_logical_emit_message). However, it requires a bit more setup on the source database – you need to create this table on every source database and give Sequin's Postgres user write access to this table. So, we opted for pg_logical_emit_message to keep the setup simpler.
Pulling this together in Elixir
Sequin is written in Elixir. To make this happen in Elixir, we have a GenServer for each stream processor:
TableReader
TableReader is responsible for orchestrating the table capture process. TableReader emits low/high watermarks and selects chunks from Postgres.
It first emits the low watermark:
payload =
Jason.encode!(%{
table_oid: table_oid,
batch_id: current_batch_id,
backfill_id: backfill_id
})
Postgres.query(conn, "select pg_logical_emit_message(true, $1, $2)", [
"sequin.table-capture.low-watermark",
payload
])
Then, it runs its select. Finally, it emits a high watermark with the same payload:
Postgres.query(conn, "select pg_logical_emit_message(true, $1, $2)", [
"sequin.table-capture.high-watermark",
payload
])
The TableReader stores its chunk in memory.
TableReader manages a cursor. The cursor (a keyset cursor) indicates where it is in the table that it is reading from. When we flush a batch from the TableReader to the output stream, we can also persist the cursor position associated with the end of the flushed batch.
If TableReader crashes or is stopped, it's safe; when it reboots, it will fetch the cursor associated with the last batch that was written to the output stream.
SlotProcessor
The SlotProcessor connects to the replication slot and processes WAL messages. When it encounters a low watermark, it updates its state, indicating it should start saving PKs for the associated table OID.
When the SlotProcessor encounters a high watermark, it makes a call to TableReader. In the call is the list of primary keys to filter out.
If TableReader has the corresponding batch, TableReader will perform the filter and flush its read messages to the output stream. If TableReader doesn't have the corresponding batch, that means it has likely been restarted since the low and high watermarks were emitted. This is an expected situation, so safe to ignore.
The call to TableReader from SlotProcessor is synchronous. When it completes, SlotProcessor drops the batch's primary keys from memory and continues processing the WAL.
Low without high?
One edge case that can emerge: The TableReader might emit a low watermark message. But then crash before it's able to complete the rest of its operation, namely writing the high watermark message.
This is bad, because the SlotProcessor will accumulate PKs in memory indefinitely.
To mitigate, SlotProcessor will check in with TableReader as its accumulated PKs grow to verify the watermark/batch is valid. If TableReader does not recognize the batch_id or is not alive, the SlotProcessor can safely discard its accumulated PKs.
Optimization
To make the table capture process fast, we want TableReader to process the biggest batch sizes that it can as fast as it can. This means filling out a large chunk with multiple, parallel queries.
In an upcoming blog post, we'll describe how this process works.
Drawbacks
The primary drawback of this approach is that it only works on tables with primary keys. Without a primary key or any other unique constraints, there's no way to uniquely identify rows. Therefore, we can't consolidate TableReader's batch with the SlotProcessor's recently-seen rows.
At the moment, Sequin does not support table capture for tables without primary keys. In the future, we'll roll out support, but probably with limitations (e.g. you can't run table capture at the same time as change capture).
Conclusion
Building a reliable CDC system with table state capture requires careful coordination between change and state capture processes. Our approach using chunked capture with watermark synchronization solves several key challenges:
- It maintains consistency without requiring table locks or pausing change capture
- It handles race conditions gracefully through PK-based filtering
- It remains memory-efficient by processing tables in chunks
- It provides recovery guarantees through cursor persistence and watermark validation
Leveraging features in both Postgres and Elixir/OTP, we've built a system that achieves both consistency and high performance.
Check out Sequin for yourself via one of our quickstarts or by creating a free trial account on Sequin Cloud.