

"Do not spur the packets; shorten the wait."
—Anon., server rack inscription, ca. 2008
In high‑throughput data pipelines, the goal is to keep CPUs saturated while avoiding memory exhaustion.
Memory exhaustion happens when pile-ups occur. Without proper back-pressure, a data pipeline can enter an out-of-memory loop (affectionately, an "OOM loop") that makes recovery very difficult: the pipeline goes down because a pile-up caused a memory spike. When it comes back up, there's only more work to do, which means a bigger pile-up and a bigger memory spike.
Elixir's GenStage provides a stellar example for how to build high-throughput data pipelines that saturate cores with back-pressure controls. We've used it to great effect at Sequin. I explain the principles of its architecture below.
Anatomy of the pipeline
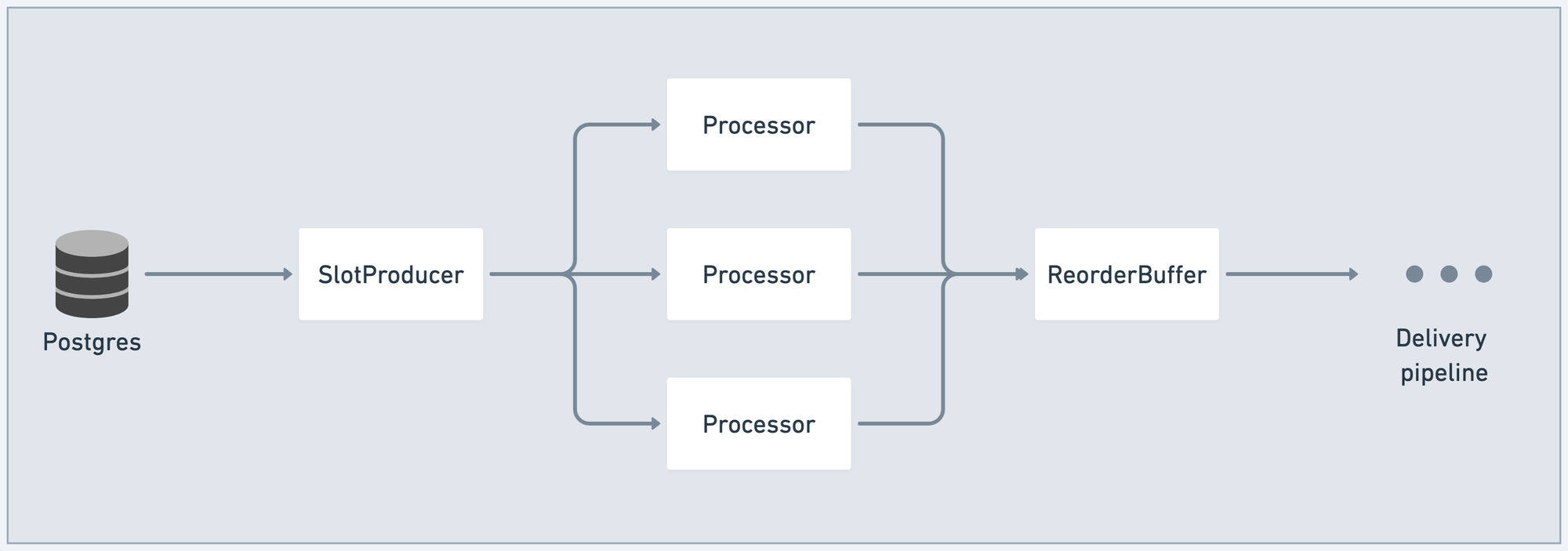
We'll use Sequin's pipeline as an example. The entrypoint to the pipeline is SlotProducer, an Elixir GenStage producer that connects to a Postgres logical replication slot.
SlotProducer ingests messages but doesn't process them. It fans out to a Processor stage, one for each CPU core. Each Processor is a GenStage ConsumerProducer. In the processor stage, Postgres binaries are parsed, values are casted, and messages are mapped to target downstream sinks (like Kafka or SQS).
Messages from the Processor stage are joined and ordered in the ReorderBuffer stage before flowing downstream for delivery:
Pushing messages
The naive way to move messages through this data pipeline is with GenServer.call/3. GenServer.call/3 is a method for passing messages between processes in Elixir. call/3 sends a message and blocks until the callee replies.
call/3 means SlotProducer will have to do a lot of waiting. And as SlotProducer waits for one Processor to accept a batch of messages, the other Processors might become available for work:
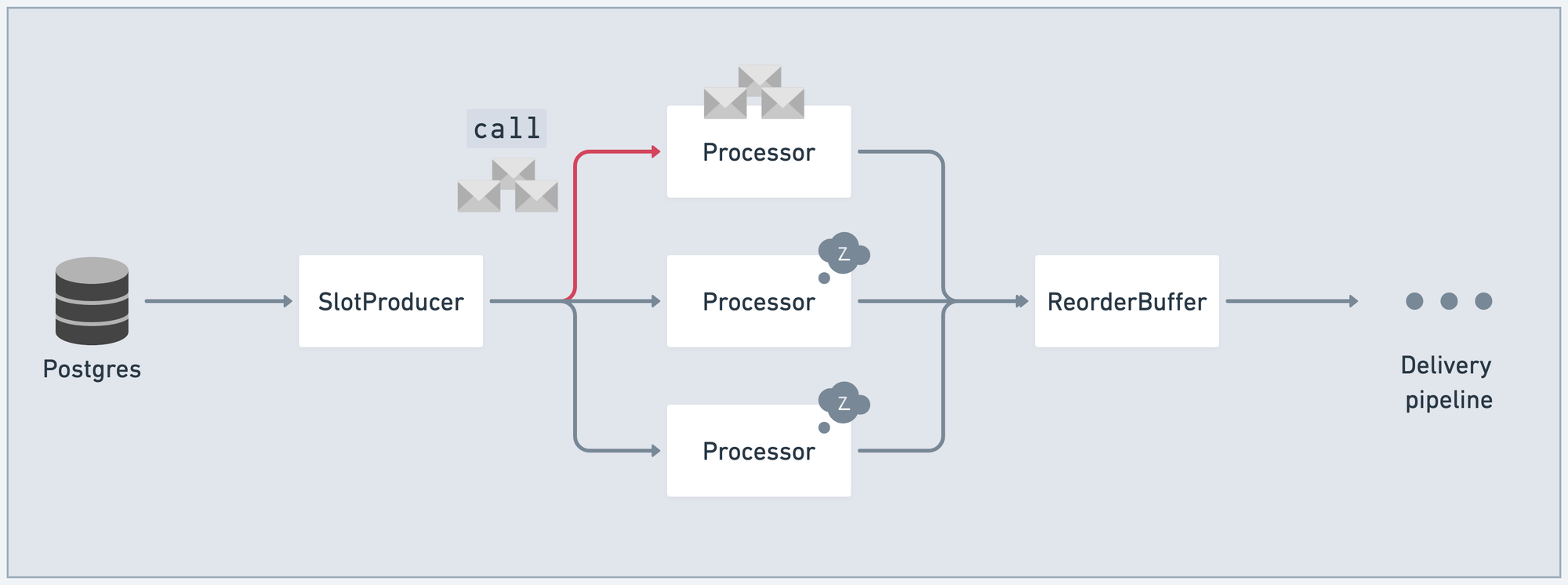
So, now SlotProducer is waiting on the first Processor to ack its batch of messages. And the other two Processor processes are idle, waiting for SlotProducer to unblock. At that point, we've violated our goal of keeping CPUs saturated.
Asynchronously pushing messages
A natural reaction is to replace call/3 with fire-and-forget GenServer.cast/2. This form of sending messages does not block the caller. SlotProducer can slip a batch of messages into a Processor mailbox, then continue working. Processor will pull the batch from the mailbox when it's ready to do so:
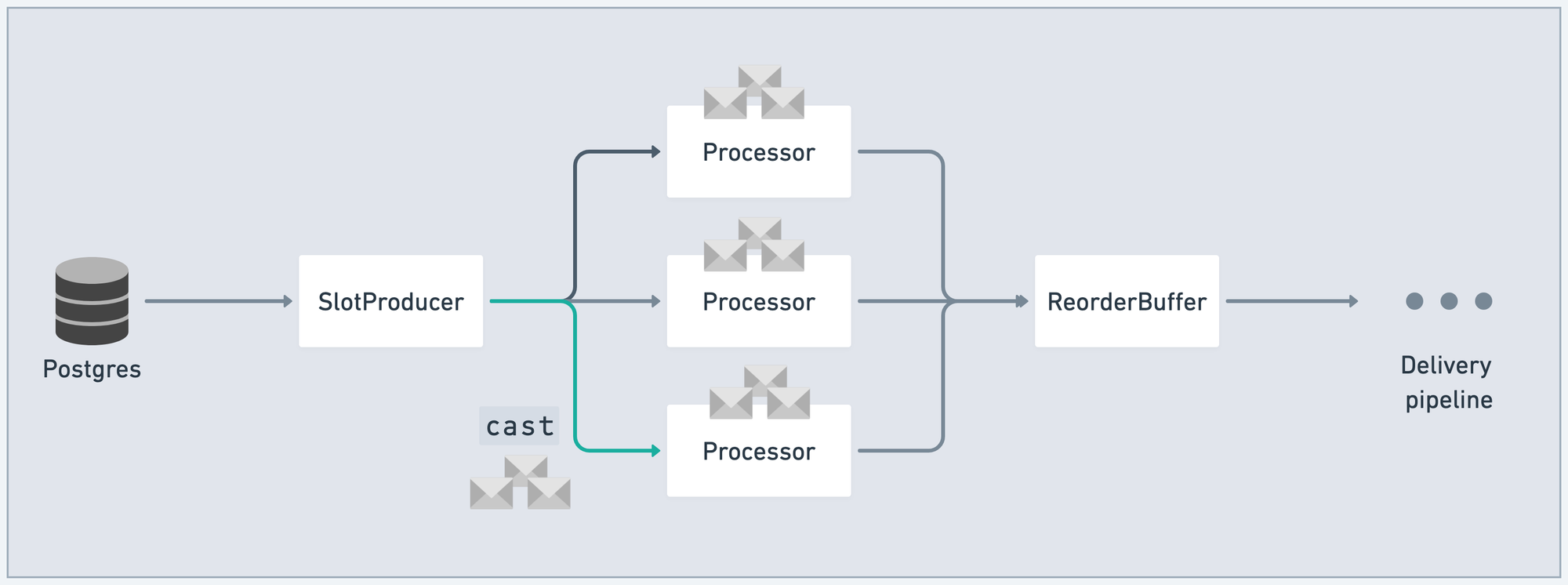
There's a big problem here, though: we open ourselves up to memory exhaustion. This strategy provides no back-pressure.
If the downstream push to e.g. Kafka is failing, messages will begin to accumulate in the system. Or if Postgres is sending messages into our data pipeline faster than the Processor stage can process them, messages will begin piling up in Processor mailboxes:
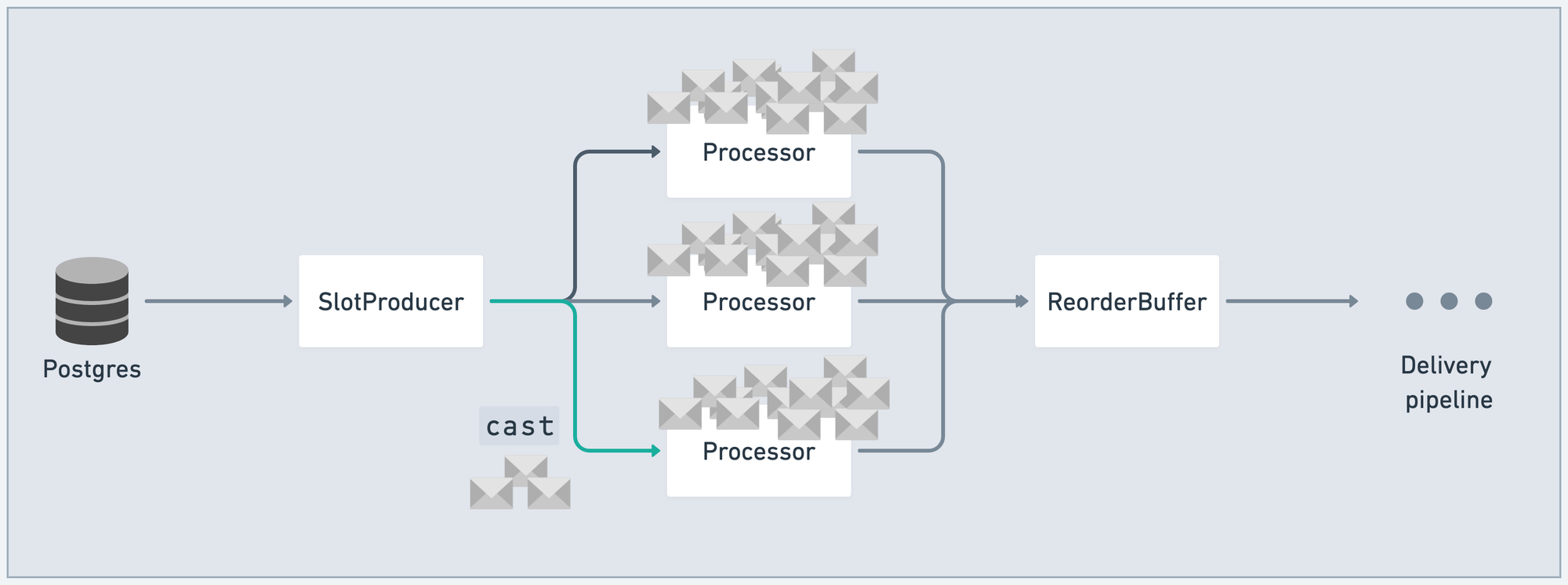
Pull-based flow with GenStage
Elixir's GenStage flips the direction: consumers demand a number of events. Producers supply at most that many:
Demand propagation
When the pipeline boots, the consumers at the end of the system (at stage N) send demand to the stage before them (stage N-1). Demand is just an integer, indicating the number of messages the stage is ready for. Demand is sent using cast/2 so that it doesn't block:
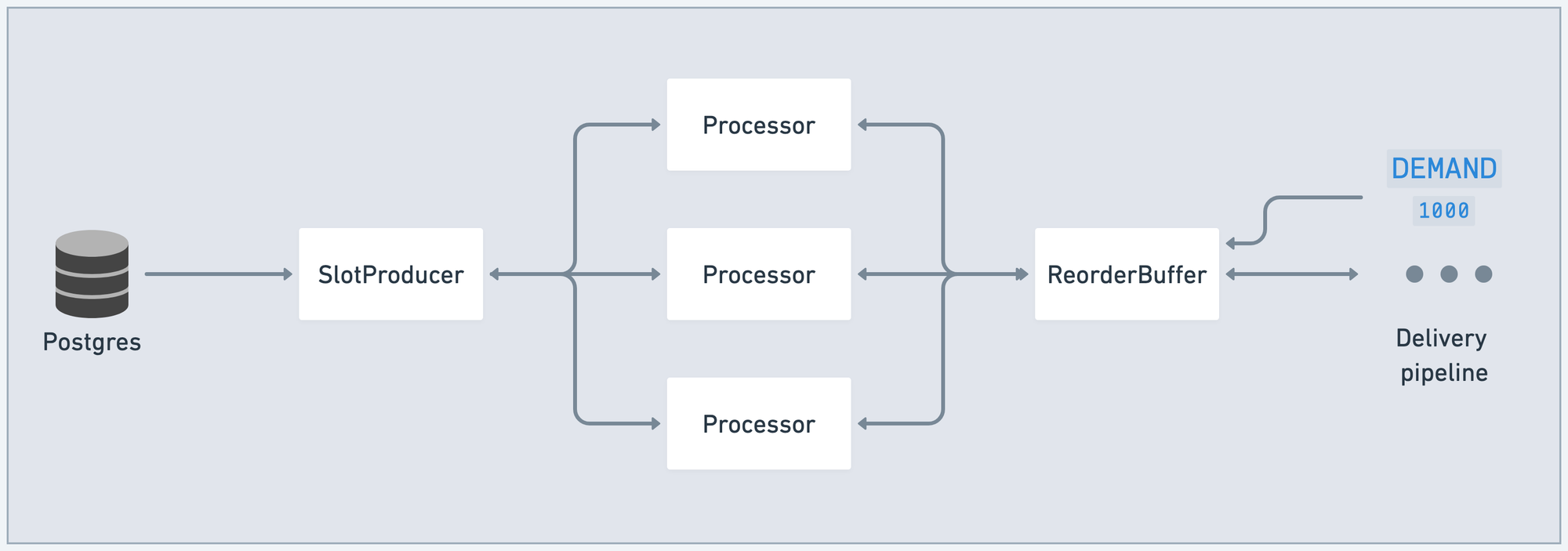
As each stage receives demand, it propagates that demand up to the prior stage. Finally, that demand reaches SlotProducer. SlotProducer keeps track of the demand it has received from each consumer:
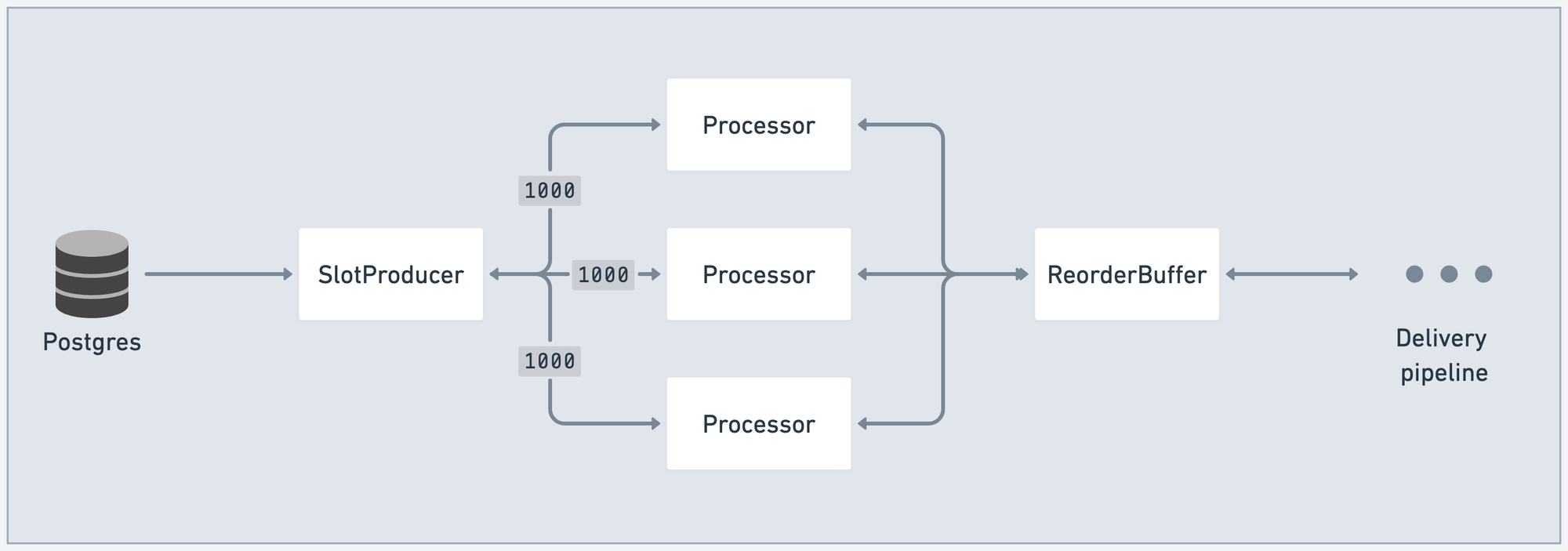
In this example, before any messages have entered the system, SlotProducer knows the pipeline has indicated it can handle 3000 messages (1000 per Processor).
Messages flow in from the Postgres replication slot. SlotProducer fans those messages out to each Processor. Importantly, it can now cast/2 those messages, because–as we'll see–demand controls for back-pressure.
As SlotProducer sends a batch of messages to a Processor, GenStage decrements that message count from the outstanding demand counter for that Processor:
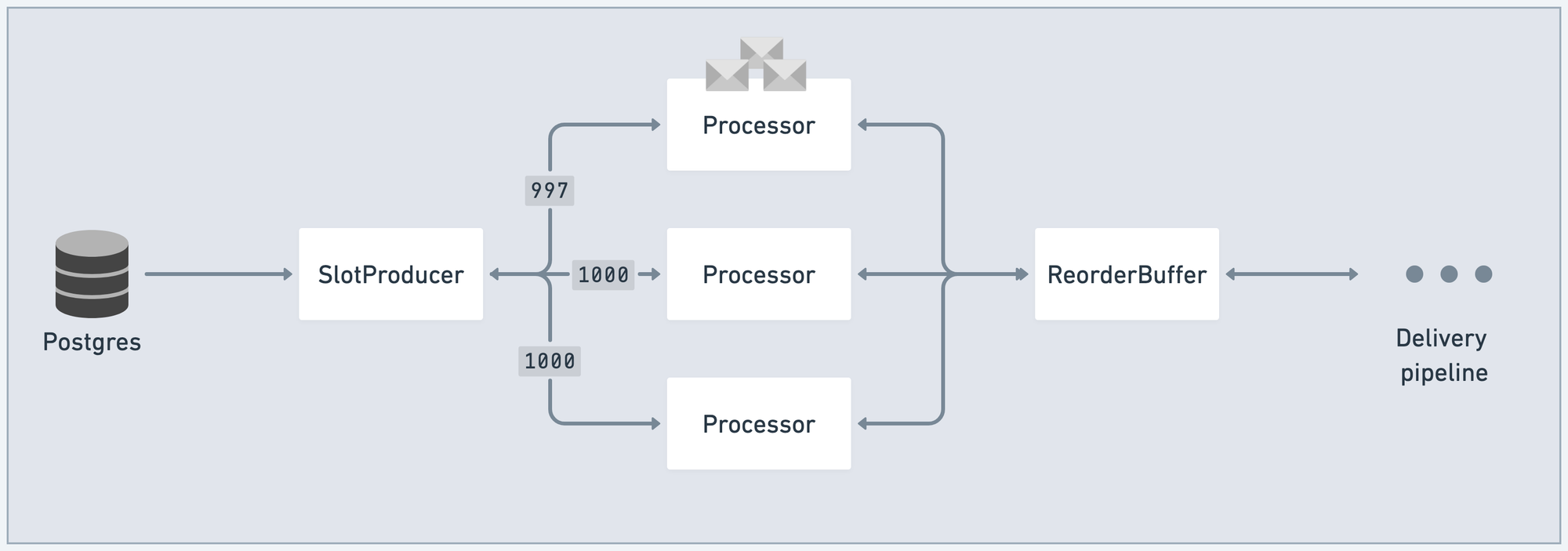
Periodically, as the end of the pipeline chews through messages, it will send new demand upstream. This is handled for you by GenStage, as consumers process messages. That demand tops up all counters.
Handling a burst
Now, here's the important bit: let's say that a giant transaction commits to Postgres. The rate of inbound messages from Postgres skyrockets.
As the pipeline saturates, the outstanding demand for each Processor falls to 0:
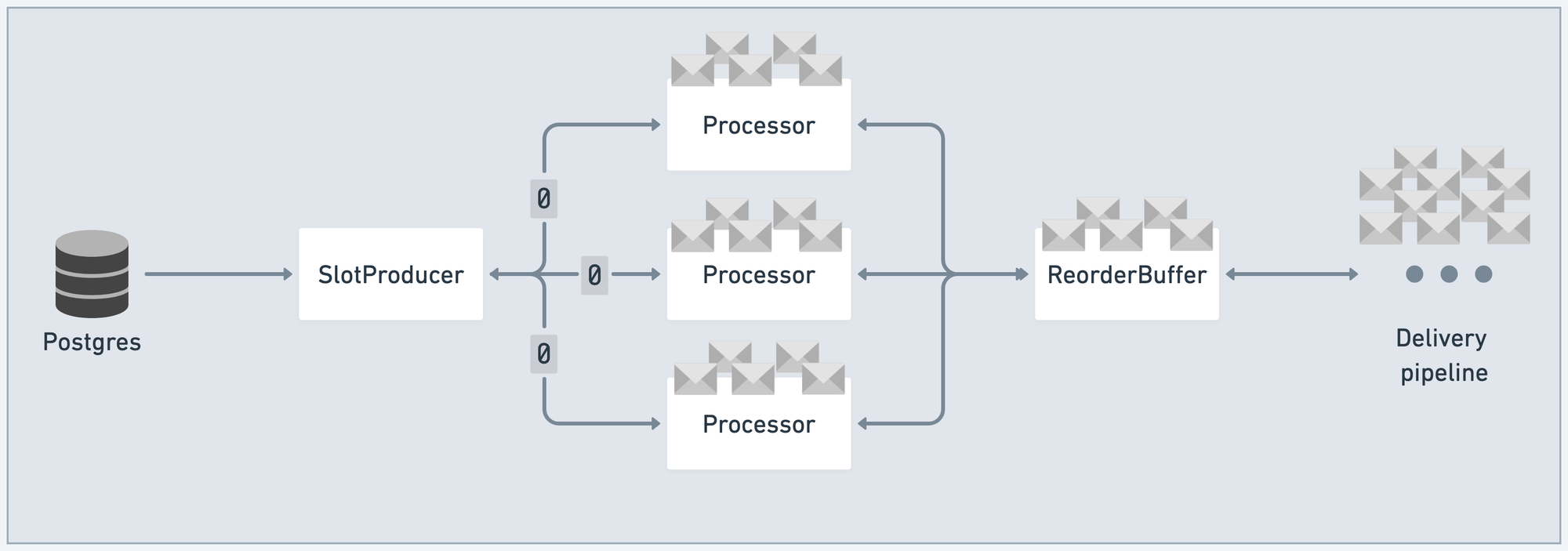
At that point, SlotProducer knows that the pipeline is saturated and doesn't have any room for more messages. It can then apply back-pressure to Postgres, in the form of not reading in any more messages from the TCP socket.
This allows our pipeline to stay saturated without blowing up memory.
So, in this way, we can use cast/2 for sending messages through the pipeline, which means no waiting. And demand gives us back-pressure, ensuring that we don't overload our system.
Going further
In addition to GenStage, there's a library built on top of GenStage called Broadway. It's a tailored version GenStage pipeline specifically focused on consuming from sources like Kafka, SQS, etc.
I also recently recorded a video where I walk through the first several commits of our very own SlotProducer if you want to see an example of a real-world GenStage producer.
Thanks to GenStage, Sequin's able to provide a low-latency data pipeline out of Postgres that easily saturates cores. That means it's fast and vertically scales nicely.